Articles
Andreas Stuhlmüller: Training ML Systems to Answer Open-ended Questions
Andreas Stuhlmüller: Training ML Systems to Answer Open-ended Questions
In the long run, we want machine learning (ML) to help us answer open-ended questions like “Should I get this medical procedure?” or “What are the risks of deploying this AI system?“ Currently, we only know how to train ML systems if we have clear metrics or can easily provide feedback on the outputs. Andreas Stuhlmüller, president and founder of Ought, wants to solve this problem. In this talk, he explains the design challenges behind ML’s current limitations, and how we can make progress by studying the way humans tackle open-ended questions.
Below is a transcript of the talk, which we’ve lightly edited for clarity. You can also watch it on YouTube or discuss it on the EA Forum.
The Talk
I'll be talking about delegating open-ended cognitive work today — a problem that I think is really important.
Let's start with the central problem. Suppose you are currently wearing glasses. And suppose you're thinking, "Should I get laser eye surgery or continue wearing my glasses?"
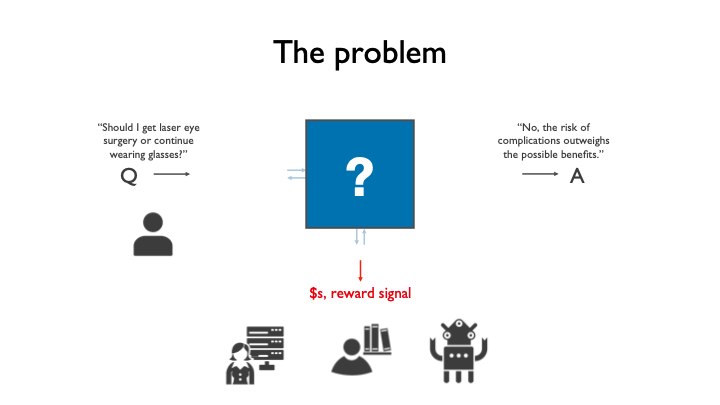
Imagine that you're trying to get a really good answer — for example, "No, the risks outweigh the possible benefits” — that accounts for your personal preferences, but also relevant facts, such as [potential] complications or likely consequences.
Imagine that there are a lot of experts in the world who could, in principle, help you with that question. There are people who have the relevant medical knowledge and people on the Internet, perhaps, who could help you think through it. Maybe there are machine learning algorithms that have relevant knowledge.
But here's the key: Imagine that those experts don't intrinsically care about you. They only care about maximizing the score you assign to their answer — how much you’ll pay them for [their expertise] or, in the case of machine learning, what reward signal you’ll assign to them.
The question that I’ll cover is “Can you somehow assign a mechanism that arranges your interaction with those experts, such that they try to be as helpful to you as an expert who intrinsically cares about you?” That's the problem.
First, I’d like to say a little bit more about that problem. Then I'll talk about why I think it's really important, why it's hard, and why I still think it might be tractable. I'll start with the big picture, but at the end I'll provide a demonstration.

Defining the problem
What do I mean by open-ended cognitive work? That's easiest to explain [by sharing] what I don't mean.

I don't mean tasks like winning a game of Go, increasing a company's revenue, or persuading someone to buy a book. For those tasks, you can just look at the outcome and easily tell whether the goal has been accomplished or not.
Contrast those tasks with open-ended tasks [like] designing a great board game, increasing the value that your company creates for the world, [or] finding a book that is helpful to someone. For those tasks, figuring out what it even means to do well is the key. For example, what does it mean to design a great board game? It should be fun, but also maybe facilitate social interaction. What does it mean to facilitate social interaction? Well, it's complicated. Similarly, increasing the value that a company creates for the world depends on what the company can do. What are the consequences of its actions? Some of them are potentially long-run consequences that are difficult to [evaluate].
How can we solve such tasks? First, we can think about how to solve any task, and then just [tailor the solution based on each] special case.
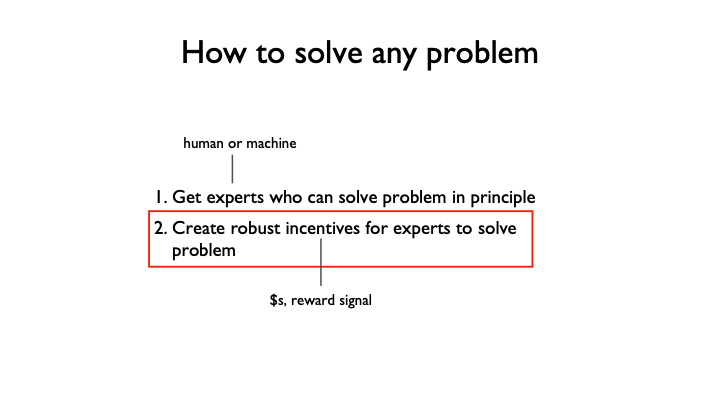
Here's the simple two step recipe: (1) find experts (they can be human or machine experts) who can, in principle, solve the problem that you're [tackling], and then (2) create robust incentives for those experts to solve your problem. That's how easy it is. And by “incentives,” I mean something like money or a reward signal that you assign to those experts [when they’ve completed the task].
There are a lot of experts in the world — and people in AI and machine learning are working on creating more. So how can you create robust incentives for experts to solve your problem?
We can think about some different instances.
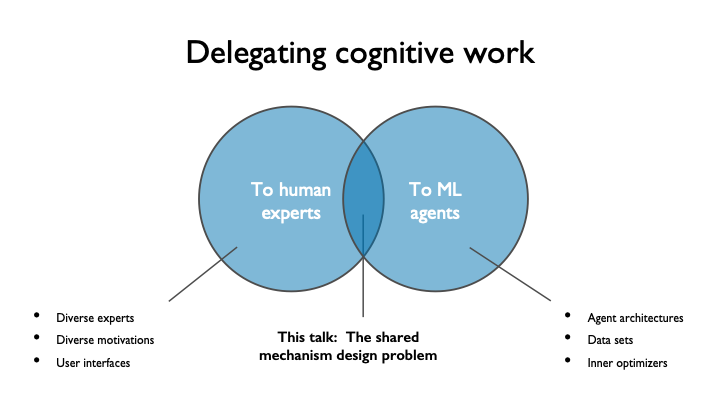
One is delegating to human experts. That has some complications that are specific to human experts, like heterogeneity. Different people have different knowledge. And people care about many things besides just money. If you want to extract knowledge from them, maybe you need specific user interfaces to make that work well. Those are [examples of] human-specific factors.
Then there are machine-specific factors. If you try to delegate open-ended tasks to machine learning agents, you want to [ask questions] like "What's a good agent architecture for that setting?” and “What data sets do I need to collect for these sorts of tasks?" And then there are more esoteric factors like what, in certain alignment problems, could go wrong for reasons that are due to the nature of ML training.
In this talk, I want to focus on the overlap between those two [human and machine experts]. There's a shared mechanism design problem; you can take a step back and say, "What can we do if we don't make assumptions about the interests of experts? What if you just [assume that experts will] try to maximize a score, but nothing else?” I think, in the end, we will have to assume more than that. I don’t think you can treat [an expert] as a black box [with only one goal]. But I think it's a good starting point to think about the mechanisms you can design if you make as few assumptions as possible.
Why the problem is important
I've talked about what the problem is. Why is it important?

We can think about what will happen if we don't solve it. For human experts, it's more or less business as usual. There are a lot of principal-agent problems related to cognitive work in the world. For example, imagine you're an academic funder who’s giving money to a university to [find] the best way to treat cancer. There are researchers at the university who work on things that are related to that problem, but they're not exactly aligned with your incentives. You care about finding the best way to treat cancer. The researchers also care about things like looking impressive, which can help with writing papers and getting citations.
On the machine-learning side, at the moment, machine learning can only solve closed-end problems — those for which it’s very easy to specify a metric [for measuring how] well you do. But those problems are not the things we ultimately care about; they're proxies for the things we ultimately care about.
This is not [such a bad thing] right now. Perhaps it's somewhat bad if you look at things like Facebook, where we maximize the amount of attention you spend on the feed instead of the value that the feed creates for you. But in the long run, the gap between those proxies and the things we actually care about could be quite large.
If the problem is solved, we could get much better at scaling up our thinking on open-ended tasks. One more example of an open-ended task from the human-expert side is [determining which] causes to support [for example, when making a charitable donation]. If you could create a mechanism [for turning] money into aligned thinking on that question, that would be really great.
On the machine-learning side, imagine what it would be like to make as much progress using machine learning for open-ended questions as we've made using it for other tasks. Over the last five years or so, there's been a huge amount of progress on using machine learning for tasks like generating realistic-looking faces. If we could, in the future, use it to help us think through [issues like] which causes we should support, that would be really good. We could, in the long run, do so much more thinking on those kinds of questions than we have so far. It would be a qualitative change.
Why the problem is difficult
[I’ve covered] what the problem is and why it's important. But if it's so important, then why hasn't it been solved yet? What makes it hard?

[Consider] the problem of which causes to support. It's very hard to tell which interventions are good [e.g. which health interventions improve human lives the most for each dollar invested]. Sometimes it takes 10 years or longer for outcomes to come [to fruition], and even then, it’s not easy to tell whether or not they’re good outcomes. There's [an element of interpretation] that’s necessary — and that can be quite hard. So, outcomes can be far off and difficult to interpret. What that means is you need to evaluate the process and the arguments used to generate recommendations. You can't just look at the results or the recommendations themselves.
On the other hand, learning the process and arguments isn’t easy either, because the point of delegation is to give the task to people who know much more than you do. Those experts [possess] all of the [pertinent] knowledge and reasoning capacity [that are necessary to evaluate the process and arguments behind their recommendations. You don’t possess this knowledge.] So, you're in a tricky situation. You can't just check the results or the reasoning. You need to do something else.
Why the problem is tractable
What does it take to create good incentives in that setting? We can [return to] the question [I asked] at the very beginning of this talk: “Should I get laser eye surgery or wear glasses?”

That's a big question that is hard to evaluate. And by “hard to evaluate,” I mean that if you get different answers, you won’t be able to tell which answer is better. One answer might be "No, the risk of the complications outweighs the possible benefits." Another might be "Yes, because over a 10-year period, the surgery will pay [for itself] and save you money and time." On the face of it, those answers look equally good. You can't tell which is better.
But then there are other questions, like “Which factors for this decision are discussed in the 10 most relevant Reddit posts?”

If you get candid answers, one could be "appearance, cost, and risk of complications." Another could be “fraud and cancer risk.” In fact, you can evaluate those answers. You can look at the [summarized] posts and [pick the better answer].
So, [creating] good incentives [requires] somehow closing the gap between big, complicated questions that you can't evaluate and easy questions that you can evaluate.
And in fact, there are a lot of questions that you can evaluate. Another would be: “Which factors are mentioned in the most recent clinical trial?”

You could look at the trial and [identify] the best summary. There are a lot of questions that you can train agents on in the machine-learning setting, and [evaluate] experts on in the human-expert setting.
There are other difficult questions that you can’t directly evaluate.

For example: “Given how the options compare on these factors, what decision should I make?” But you can break those questions down and [evaluate them using answers to sub-questions].
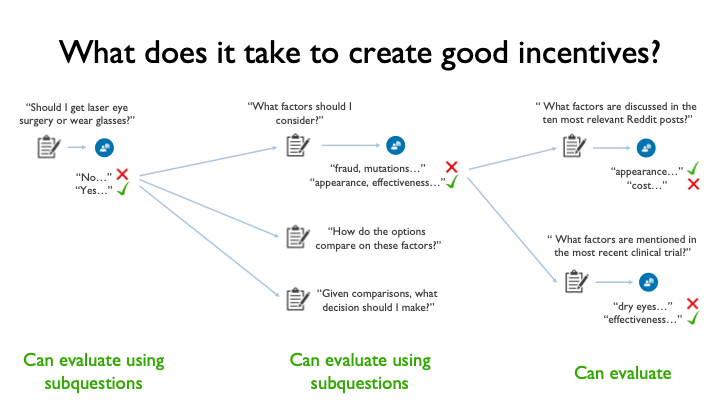
Step by step, you can create incentives for [experts to provide useful answers to] slightly more complex questions, [and gradually build up to] good incentives for the large questions that you can't directly evaluate.
That's the general scheme. We call it “factored evaluation.”

A demonstration of factored evaluation
We'd like to test this sort of mechanism on questions that are representative of the open-ended questions that we care about in the long run, like the laser eye surgery question.
This is a challenging starting point for experiments, and so we want to create a model situation.
One approach is to ask, "What is the critical factor that we want to explore?"
It’s that gap between the asker of the question, who doesn’t understand the topic, and the experts who do. Therefore, in our experiments we create artificial experts.
For example, we asked people to read a long article on Project Habakkuk, which was a plan [the British attempted during World War II] to generate an aircraft carrier [out of pykrete], which is a mixture of [wood pulp] and ice. It was a terrible plan. And then someone who hasn’t read the article — and yet wants to incentivize the experts to provide answers that are as helpful as reading the article would be — asks the experts questions.
What does that look like? I'm going to show you some screenshots from an app that we built to explore the mechanism of factored evaluation. Imagine that you're a participant in our experiment.
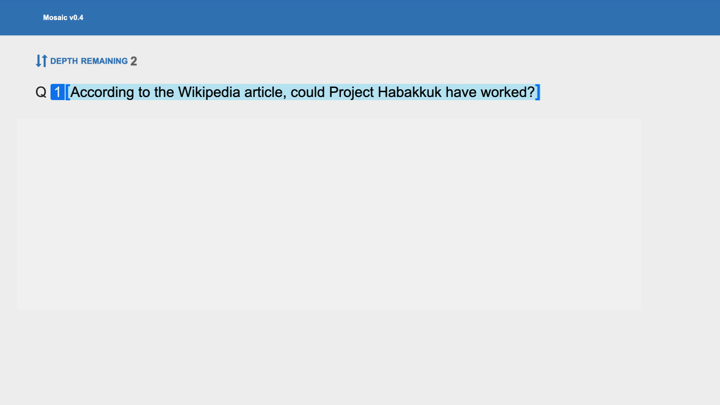
You might see a question like this: "According to the Wikipedia article, could Project Habakkuk have worked?"
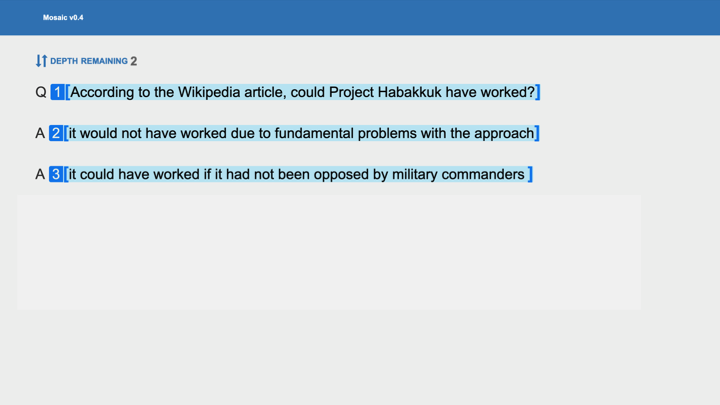
And then you’d see two answers: "It would not have worked due to fundamental problems with the approach” and "It could have worked if it had not been opposed by military commanders."
If you don't know about this project, those answers look similarly plausible. So, you're in the situation that I mentioned: There's some big-picture context that you don't know about, yet you want to create good incentives by picking the correct answer.
Imagine you’re in a machine-learning setting, and those two answers are samples from a language model that you're trying to train. You want to somehow pick the right answer, but you can't do so directly. What can you do? Ask sub-questions that help you tease apart which of the two answers is better.
What do you ask?
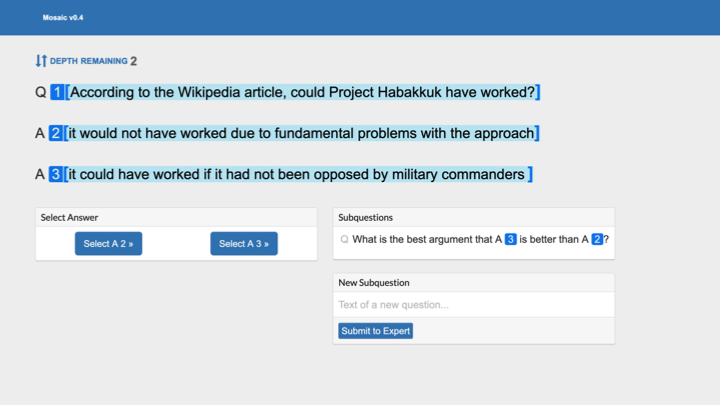
One [potential question] is: "What is the best argument that the second answer [‘Project Habakkuk would not have worked due to fundamental problems with the approach’] is better than the first?" I'm not saying this is the best thing to ask. It’s just one question that would help you tease apart which is better.
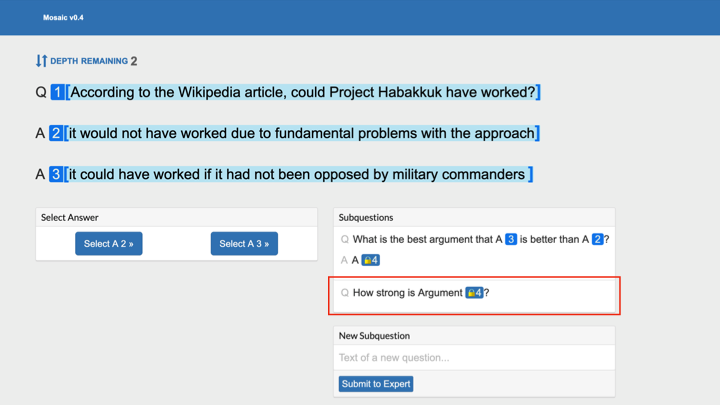
The answer might provide an argument, which would then allow you to ask a different question, such as “How strong is that argument?” So, you can see how, using a sequence of sub-questions, you can eventually figure out which of those answers is better without yourself understanding the big picture.
Let's zoom in on the second sub-question [“How strong is that argument?”] to see how you can eventually arrive at something that you can evaluate — the argument being, in this example, that [the science television show] MythBusters proved that it's possible to build a boat out of pykrete. That contradicts one of the two answers.
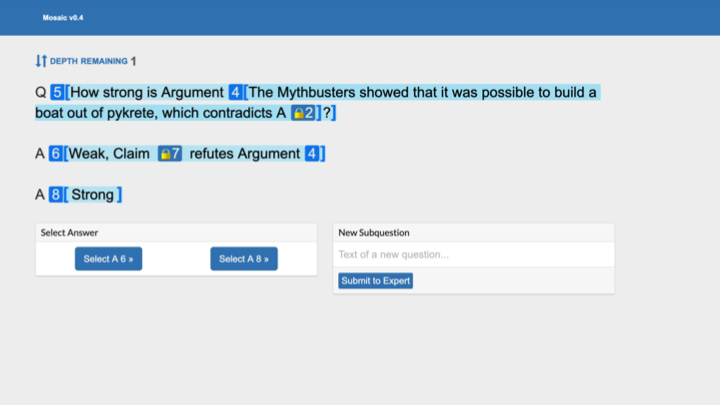
[Another set of two answers] might be "There are some claims that refute it” and "It's a strong argument." Once again, those claims are too big to directly evaluate, but you can ask additional questions, like "If [a given claim] is true, does it actually refute the argument?"
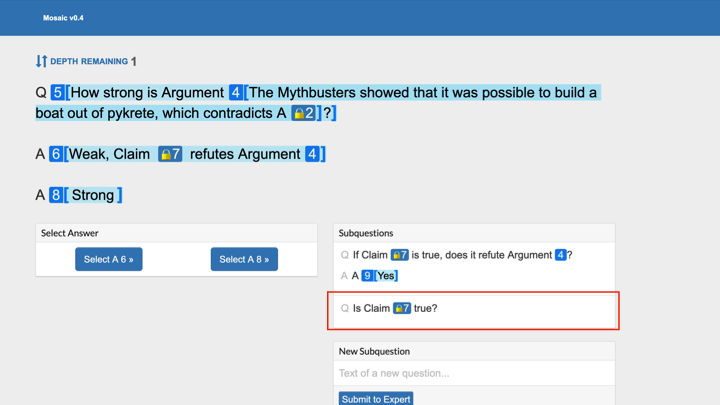
Maybe you get back a yes. And then you can ask, "Is the claim true?" In this way, you can break down the reasoning until you’re able to evaluate which of the answers is better — without understanding the topic yourself.
Let's zoom in on the claim that the MythBusters built a small boat of pykrete.

You could ask, “Is it true that they didn't think it would work at scale?” You’d receive two answers with different quotes from the Wikipedia article. One says they concluded that pykrete was bulletproof and so on. And the other says they built a small boat, but they doubted that you could build an aircraft carrier. And in that case, it's easy to choose the correct answer; in this case, the second is clearly better.
So, step by step, we've taken a big question, [gradually distilled it] to a smaller question that we can evaluate, and thus created a system in which, if we can create good incentives for the smaller questions at each step, we can bootstrap our way to creating good incentives for the larger question.
That's the shape of our current experiments. They're about reading comprehension, using articles from Wikipedia. We've also done similar experiments using magazine articles, and we want to expand the frontier of difficulty, which means we want to better understand what sorts of questions this mechanism reliably works for, if any.
One way we want to increase the difficulty of our experiments is by increasing the gap between the person who's asking the question and the expert who’s providing answers.
So, you could imagine having experts who have read an entire book that the person who's asking the questions hasn't read, or experts with access to Google, or experts in the field of physics (in the case where the asker doesn't know anything about physics).
There's at least one more dimension in which we want to expand the difficulty of the questions. We want to make them more subjective — for example by using interactive question-answering or by eventually expanding to questions like "Should I get laser eye surgery or wear glasses?"
Those are just two examples. There's a very big space of questions and factors to explore.
We want to understand [the conditions under which] factored evaluation works and doesn't work. And why? And how scalable is it?
Let's review.
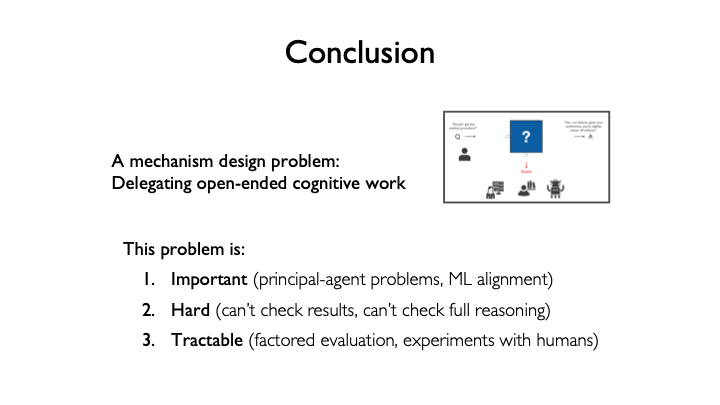
I've told you about a mechanism design problem: delegating open-ended cognitive work. I've told you that this problem is important because of principal-agent issues with cognitive work that you face everywhere in human day-to-day life, and with machine-learning alignment. I've told you that it's hard because you can't just check the results you get from experts, but you also can't check their full reasoning. That's a tricky situation.
But I've also told you that it's tractable. We have some ideas — including factored evaluation — that can help us get some traction, even if they're not ultimately the correct solution. And we can experiment on them today with humans and see whether they work or not, and if not, how they could be changed so that they work better.

If you're excited about this project, join us at Ought.
Moderator: Thanks very much. My first question is about timelines. How long has it taken you to get this far, and [what progress do you expect to make] in the next one, five, or 10 years?
Andreas: Yeah. So far, a lot of our work has [centered on] figuring out what kinds of experiments to run [in order to] get any evidence on the question of interest. I think there are a lot of ways to run experiments that are busy work [and don’t allow] you to actually learn about the question you care about. It took a lot of iteration — roughly six months — [to reach] the current setting. And now the game is to scale up and get more participants. Over the next year or so, we hope to get, for limited sets of questions, relatively conclusive evidence on whether the scheme can work or not.
Moderator: Any questions from the audience?
Audience Member: You mentioned incentives a lot, but I didn't quite understand how the experts, in your example of Wikipedia, were actually incentivized to give the right answer.
Andreas: Yeah, this is a subtlety I skipped over, which is where the expert answers come from and how, exactly, they’re generated. In our case, one expert is simply told to generate a helpful answer: "Read the article and try to be as accurate and honest as possible."
The other expert is told, "Your goal is to trick the human judge into choosing the wrong answer. You win if you make an answer that seems plausible, but is actually wrong, and if someone were to read the entire article, they would clearly see it as wrong." So, they have opposing incentives, and are rewarded based on whether they trick the judge into accepting the wrong answer.
Moderator: So, is the honest actor rewarded?
Andreas: In the long run, that's the way to do it. At the moment, we rely on participants just doing the right thing.
Moderator: Okay, great. Please join me in thanking Andreas for his time.